 Cloud
Cloud
 Data & AI
Data & AI

In today’s technology-driven world, bringing new and higher quality services to market fast is critical for business success. Plus, to stay ahead of the competition, organizations must provide reliable services while continuously looking for ways to accelerate innovation and enhance the consumer experience. With customer expectations and demands of digital services adding pressure to iterate faster, organizations are adopting modern software development practices that speed the deployment of new features but in turn create difficulties to ensure the reliable operation of multiple systems.
Site Reliability Engineering (SRE) practices help organizations optimize the reliability of their IT systems, bringing value to market faster and improving profitability. As a result, the role of Site Reliability Engineer has become one of the fastest-growing roles in IT infrastructure teams.
What is the role of Site Reliability Engineers?

Basically, a Site Reliability Engineer is responsible for maintaining an organization’s IT systems running smoothly. More specifically, SREs are in charge of “availability, latency, performance, efficiency, change management, monitoring, emergency response, and capacity planning.”
SREs are involved in selecting architectural solutions and assessing how they will affect the stability of the entire system. In addition, as the role implies software development skills, SREs are also in charge of overseeing the core technical components and dealing with incident response. In fact, the role of a Site Reliability engineer is quite flexible. They can be responsible for a variety of things, such as reviewing the code or writing tests–everything vital to maintaining a strong track record of a system’s reliability.
Moreover, as enterprises are embracing today’s technological challenges and adopting modern development practices and cloud-native technologies, it has opened the doors for observability. As such, the quality of a system’s observability has become significant in helping SRE professionals achieve their goals.
Understanding observability

First of all, let’s clarify the interdependence between monitoring and observability concepts. Monitoring stands for the set of activities that IT specialists perform to ensure observability, which is, in fact, a property of a system.
Observability assumes that a system’s internal state can be measured by analyzing its outputs. If a system is “observable,” SRE teams can get data-driven insights on its current state and improve its performance as needed. Plus, this property allows them to quickly determine what exactly went wrong and what the state of the system was at that moment.
How SREs and observability are connected
To ensure a system’s observability, organizations need to collect and analyze loads of performance telemetry data. With proper tooling, it is possible to gather and process this data promptly—often in real-time.
Based on such data analysis, SRE teams can obtain data-driven insights on the errors taking place within a system and the reasons for their occurrence. These insights, in turn, should help SREs with improving the overall reliability of applications.
As we can see, improving observability correlates with the goals of SRE specialists. The more observable the system is, the more opportunities SREs get to assess its state from different perspectives and improve its stability and performance.
The benefits of observability for SREs
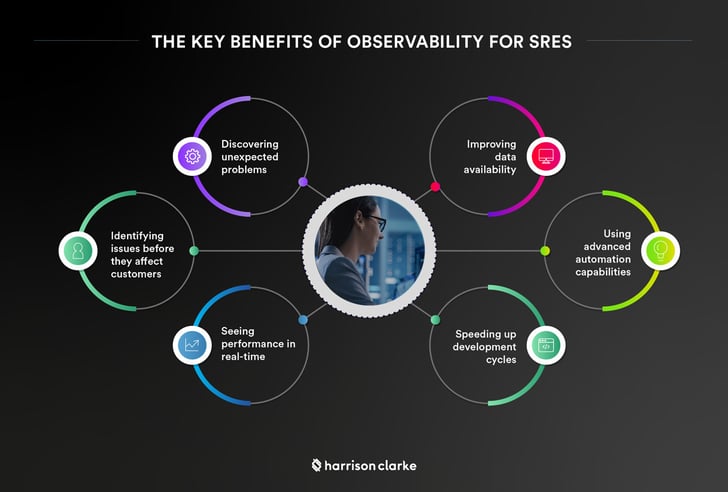
Here are some of the particular benefits SREs can obtain from a system’s observability.
Discovering unexpected problems
Using familiar tools to monitor the health of systems often involves observing specific variables — the metrics that IT specialists typically use for tracking. A system’s observability allows discovering those conditions that SRE teams had not even considered before (the “unknown unknowns”) and correlating them further with specific issues.
Identifying issues before they affect customers
With observability in place, SREs get better visibility of the changes that have occurred in the system, their effect on the processes, and problems they generate. This allows fixing issues early — before their impact becomes critical.
Seeing performance in real-time
Working with distributed systems often makes understanding the actual performance indicators quite difficult. When a system is observable, SRE teams have real-time visibility into production environments, which allows them to better handle the obstacles to improving reliability promptly.
Improving data availability
Figuring out what the system looked like before the last deployment is often a challenging task. To get this information, SRE professionals may have to turn to third-party providers and applications. However, with an observable system, this data becomes readily available.
Speeding up development cycles
A system’s observability helps troubleshoot problems more efficiently and quickly, thus greatly accelerating the software development and delivery processes.
Using advanced automation capabilities
System observability goes hand in hand with the emerging opportunities for processes automation. For example, SREs can automate telemetry collection, set up automatic error correction, and get predictive calculations of the likelihood of problems arising based on analysis of system outputs.
Observability benefits SRE teams and the business

As the reliability of the systems, services, and products is gaining critical importance for organizations, the role of Site Reliability Engineer continues to grow. It is the SRE professional who is at the forefront when it comes to providing uptime for high-load services, stabilizing a system after a crash, and making the appropriate amendments to the code.
Observability supports SREs in meeting reliability and performance goals. When a system is observable, SREs can better identify problems and fix them in time, keep track of the current state of things and accelerate the development cycles. When teams can release new features quickly without compromising systems’ stability, observability generates significant value for the business.



